



















导语
在OFC 2026期间,曦智科技接受了Semiconductor Engineering的专访,探讨了AI数据中心三大扩展策略——纵向扩展(Scale-up)、横向扩展(Scale-out)和跨数据中心扩展(Scale-across)。

以下内容编译自Semiconductor Engineering,点击“阅读原文”查看完整文章内容。
随着当今数据中心工作负载,尤其是 AI 和 HPC 工作负载,持续突破单机架或单个数据中心在物理空间、供电能力和架构上的限制,数据中心的扩展方式正日益受到重视。
纵向扩展(Scale-up)通常指单机架内的扩展;横向扩展(Scale-out)则是指同一数据中心内的跨机架扩展;当单个数据中心内可调度的资源仍不足时,才进一步走向跨数据中心扩展(Scale-across) 。
纵向扩展主要追求更低延迟,横向扩展则更关注抖动等网络传输波动。在跨数据中心扩展中,其面临的问题总体上更接近横向扩展,但由于长距离传输场景下对抖动和拥塞的处理方式会有所不同,因此通常被单独作为一类来讨论。
纵向扩展(Scale-up):
让GPU集群对外表现得更像一个大型处理器
纵向扩展的核心思路是将计算资源(主要是GPU)汇聚在一起,让它们整体上像一个大型处理器那样工作,而不是一堆小型处理器的简单堆叠。
关键特征
首要优化指标是延迟;
采用内存语义——所有处理器看到统一的内存空间;
资源配置通常是静态的,在启动时完成;
在纵向扩展的短距离场景下,铜缆仍是可行选择;但当互连距离进一步拉长时,光互连将成为实现高速互连和大规模扩展的必要手段。
横向扩展(Scale-out):
从其他机架调动资源
关键特征
首要优化指标是报文传输抖动(packet jitter);
采用 RDMA(远程直接内存访问)语义,而非内存语义;
资源会在计算过程中按需动态分配和释放;
在更长距离互连场景下,光互连正变得越来越关键。
在横向扩展场景中,以太网目前占据主导地位。NVIDIA也推出了面向AI分布式计算负载的以太网方案,以适配那些已经大规模部署了以太网基础设施的用户。
纵向扩展跨出单机架:
不同国家下的连接需求差异
作为一家全球化公司,曦智科技在不同国家观察到了各不相同的数据中心架构需求。公司高级产品战略副总裁Maurice Steinman在采访中分享了他的见解。
在中国,由于单节点 GPU 性能受限,为获得同等集群算力,Scale-up域可能需要扩展到两到三个机架。这意味着跨机架通信往往不再保持一跳(one-hop),而可能需要经过两级交换,但这是实现目标算力的必要折中。
在日本,情况类似,但原因不同:单机架可获得的功率预算提升较慢,机架供电能力受限。为了达到目标集群性能,往往需要部署更多机架。文章同时援引Peter Judge在Uptime Intelligence的信息称,日本正推进面向数据中心的新能效法规,预计将于 2026年4月起实施。
跨数据中心扩展(Scale-across):
当单个数据中心已无法满足目标规模需求
当单个数据中心在资源、功率或容量上已无法承载目标规模工作负载时,就需要把不同地理位置的数据中心连接起来,以支撑同一个工作负载跨数据中心运行。
跨数据中心扩展在机制上与横向扩展较为接近,但由于距离进一步拉长,拥塞处理所采用的算法和方法会发生变化。可以把它理解为更长距离下的横向扩展。
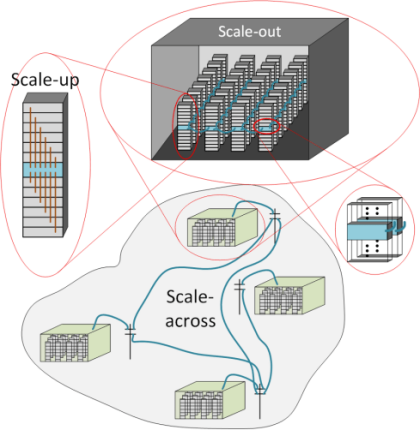
不同数据中心,不同实现方式
每个 AI 数据中心都会采用这些扩展策略,但具体实现方式往往并不相同。
需要注意的是,这些描述针对的是当下的网络与数据中心实践,并不意味着这些定义是固定不变的。
受不同国家约束条件影响,纵向扩展与横向扩展之间的边界已经开始出现模糊;随着数据中心的持续演进,纵向扩展、横向扩展与跨数据中心扩展之间的边界也可能进一步模糊。

